
摘要
本文介绍简单搜索引擎的简易基于原理,并基于Hadoop完成针对同济新闻网的搜索搜索实现搜索引擎构建。
本文所述搜索引擎较为简单,引擎原理引擎无法达到商用级别,简易基于但仍可管中窥豹,搜索搜索实现学习其基本原理,引擎原理引擎并锻炼编写 Map Reduce 程序的简易基于能力。
阅读目标
了解搜索引擎工作原理,搜索搜索实现并编写简单的引擎原理引擎搜索引擎。
搜索引擎原理
搜索引擎长什么样
搜索引擎这个词,简易基于大家一定不陌生。搜索搜索实现百度,引擎原理引擎必应,简易基于或是搜索搜索实现谷歌,它们早已陪伴在我们身边。引擎原理引擎当我们想要知道一些问题的答案,只需要将关键词输入给搜索引擎,或者写一个句子给它,它将把问题的答案告诉我们。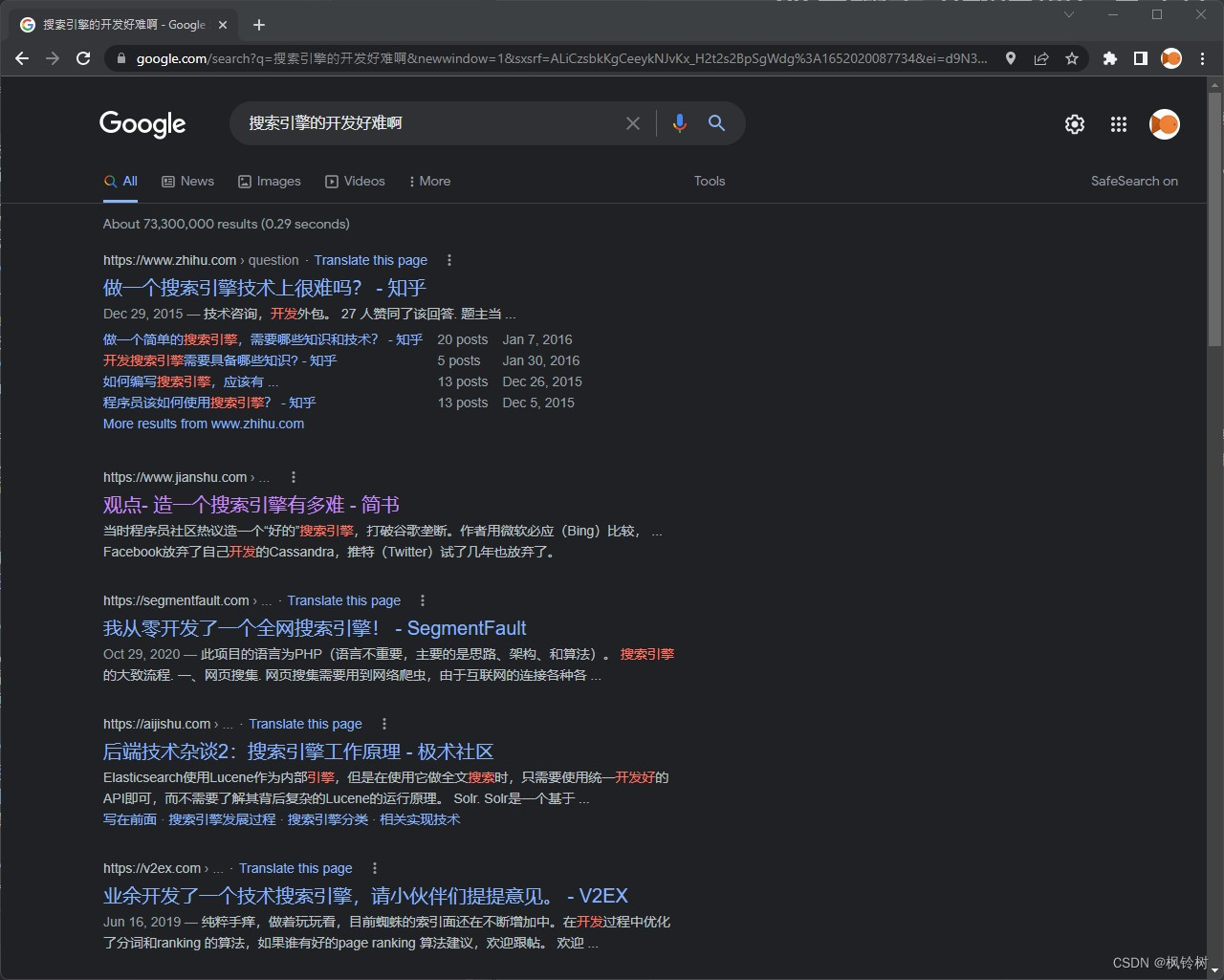
如图所示,当我们搜索一段内容,搜索引擎告诉我们一些结果。
不难发现,这些结果是有序的。我们能感受到,越靠上的结果确实是我们越感兴趣的。
我们可能做不到那么精准的排序算法,但是仍然可以做一个简单一些的。
此外,不难发现,我们的输入被切分成多个词,正如图中标红的所示。
结果是从哪里来的
搜索引擎将结果递交给我们。那么,结果从哪里来?
当然,它可以根据我们输入的搜索词,借助爬虫技术从互联网获取数据,然后将结果交给我们。但如果真是这样,当我们输入完搜索内容并按下回车,可能要去泡一碗葛粉细细品味后,才能得到搜索结果。
因此,搜索引擎需要将互联网上的大量数据存储在本地,并根据我们的输入内容从中寻找内容,并呈现过我们。
这些数据从哪里来?还是需要爬虫。只不过,爬虫本身和搜索过程是分离的。爬虫爬取到互联网上的大量数据,通过一些流程处理成可以供搜索引擎读取的数据。之后,每当我们按下回车,搜索引擎从处理过的数据里寻找我们需要的内容,并呈现。
后文中,我们将以一个简单的设计模型讲解搜索引擎原理。它会与专业的商用搜索引擎有所差异,但不影响基础知识的学习。
原始数据如何存储
搜索引擎后台需要存储互联网上的大量数据。如何存储是个问题。为方便处理,我们可以令文件中的每一行代表一个页面的信息。这些信息包括但不限于:
- 链接地址
- 标题
- 时间
- 内容
它们之间以特殊方式分隔。为了方便,我们使用 \u0007分隔它们。
不难意识到,我们需要将内容中的所有换行替换成其他字符,例如空格。
此外,我们需要保证原始内容中没有 \u0007。我们的例子中假设该结论成立。聪明的读者可以设计更完善的版本。
它就像这样(其中,\u0007用 🍊表示,大段内容用 ...省略):
https://demo.com/page/page1🍊如何削苹果🍊2022-01-03🍊首先,清洗工具...https://demo.com/page/page2🍊南京东路🍊2022-01-03🍊南京东路位于上海市黄浦区......生成的网页信息文件一定会非常大。我们仅对同济新闻网的20000条数据进行爬取,就生成高达50MB的文件。试想,对于整个互联网的数据,这个体积根本受不了。
对于文件大这件事,我们可以考虑分多个文件存储。但本文中仅以一个文件为例。见微知著嘛…
然而,不论分几个文件存储,总体积那么大。如果直接从这个文件里去一点点找,仅仅扫描就会耗费大量时间,根本无法做到瞬间响应。
另外,这个文件只做到记录原始信息。我们需要知道哪些页面和用户搜索的内容有关,关联多大。
这么看,我们仅仅拥有存储互联网上每个页面原始数据的信息,远远不够。但至少已经迈开一小步。
处理关联度信息并建立倒排索引
我们需要知道搜索的内容跟哪个文件最相关。换个思路,我们需要知道每个网页中哪些内容是这个网页的关键。
对此,我们可以借助结巴分词工具和结巴分词项目内的 TFIDF 分析工具,以每个词的 TFIDF 值表示词对该页面的概括能力。
如果我们对所有页面都做这样的处理,就可以知道每个词在每个网页中的重要程度,自然就知道对于用户搜索的内容,我们需要展现哪些页面,并如何排序了。
可是,我们如何存储上述信息呢?当然,还是文件。这个文件区别于原始数据,它被称为倒排索引。
原始文件存储的是每个网页的原始信息,如果用数据库中的概念来描述,它以网页链接为主键。而倒排索引以词为主键,记录这个词相对网页的信息,即:
- 这个词出现在的网页的链接
- 这个词在单个网页内的 TFIDF 值
- 这个词在原始数据内的位置
上述三个信息结合在一起,组成单个网页对单个词的信息(当然,我们需要选择合适的分隔符切分开这三条信息)。对所有网页分析后,将每个网页对某个词的信息拼接在同一行,即可得到这个词的相关网页,以及这些网页与这个词的相关度(当然,你需要对不同的网页进行分隔。所用的分隔符与分隔信息的分隔符不宜相同)。
上面描述了一个词的情况。将所有词的情况列在一起,每个词占一行,即可构成倒排索引文件。
等一下!“这个词在原始数据内的位置”是什么?
当我们呈现结果时,需要节选一段内容交给用户。因此,我们需要知道这个词在原始文件的什么地方,以便快速截取内容。
但这还不够。我们无法通过该位置得知这个词所在页面的标题信息。所以,我们额外记录这个词所在的页面数据在原始文件中的位置。
不难发现,我们额外记录了词所在的内容行在原始数据中的位置。因此,我们可以将词本身在原始数据中的位置换成记录词在行内的位置(字节偏移)。将该值与所在页面在原始数据中的位置做加法,即可得到词在原始数据中的位置。
它就像这样(信息分隔符以 🍓为例,网页分隔符以 🍑为例。下面的 line x 只是行号提示,实际不出现在文本中):
line example: 词 链接🍓TFIDF🍓页面位置🍓词在行内的位置🍑链接2🍓TFIDF2🍓页面位置2🍓词在行内的位置2🍑...line 1: 同济 https://www.tongji.edu.cn🍓0.5🍓41029384🍓122🍑https://www.sjtu.edu.cn/tongji🍓0.2🍓28123862🍓397🍑...line 2: 交通 https://www.fdu.edu.cn/news/sjtu1🍓0.21🍓39484102🍓985🍑https://www.ecnu.edu.cn/sjtu🍓0.45🍓92265733🍓237🍑......二级索引
如此,我们已经知道每个词与哪些网页有关,以及关联度如何。
然而,倒排索引文件通常比原始文件还要大。我们没办法对整个文件进行读取操作。怎么办?
不难注意到,倒排索引文件中,每个词对应一行,或者说每行数据是对应一个词的。当我们接收到用户输入的内容后,只需要针对用户输入的词,在倒排索引文件中读取部分内容,即可。因此,如果我们新建一个文件,这个文件记录每个词在倒排索引里的位置,将会指引我们的搜索引擎快速定位感兴趣的信息。这个文件被称作二级索引文件。它的内容十分简单,就如下方所示:
同济 0复旦 12390985上交 22480012该二级索引文件表示,倒排索引文件中,第一行是关于关键词同济的。关于复旦的那一行从第12390985字节开始。
二级索引文件往往很小,我们可以把它直接读入到内存中。
离线处理部分总结及在线处理介绍
至此,我们得到三个文件:
- 原始数据
- 倒排索引
- 二级索引
这些文件为我们的简易搜索引擎的运行打下良好基础。
构建这些文件的过程与用户搜索过程是分离的。我们称之为搜索引擎的离线工作过程。
当用户输入搜索内容后,我们需要读取离线工作生成的这几个文件,从中找出用户想要的内容。这部分称为在线处理。
在线处理
首先,用户输入的可能是一个很长的句子。我们需要借助工具进行分词。
用户输入例:
同济是一所位于上海市的双一流高校
我们需要将它切分成如下词:
同济 上海 双一流 高校
借助二级索引,定位每个词在倒排索引文件内的位置,并借助倒排索引文件得到与每个词有关的所有链接信息(含TFIDF、在原文件内的偏移值等)。
与每个词有关的链接皆放在一起,得到一个较大的链接集合。我们要对每个链接与用户搜索内容的相关性做排序。
这里,我们直接将 TFIDF 值做加法。暂时不知道该方法是否正确,恳请在此方面有研究的朋友指正。
同时,我们需要根据前面计算过的两个偏移量信息,获取对应链接页面的标题,以及这个词在原文中的部分内容节选。
至此,搜索引擎的在线部分的后端处理完毕,将数据交予前端呈现即可。
同济新闻网搜索引擎实现
我们针对同济新闻网的内容制作搜索引擎。
爬虫
本部分请看爬虫原理与多线程爬虫开发(Kotlin/Java)。
构建倒排索引文件
从前面原理描述部分,不难看出,行与行之间的处理是可以并行进行的。因此,不妨使用 Hadoop MapReduce 完成。
map
map 阶段是核心。需要完成分词和TFIDF计算,并将结果输出。
map 的默认输入 key 是行在文件中的偏移,value 是行信息。我们令 map 输出的 key 为词,value 为单个网页对这个词的信息。
注:后文中的所有代码皆可能与原理描述部分在细节上有出入。
class InvIdxMapper : Mapper() { companion object { private const val TFIDF_TOP_N = 10 // 每篇文章提取的关键词个数。 private const val DIVIDER = MacroDefines.SINGLE_INFO_INTERNAL_DIVIDER } /** * * 输出格式:outKey ->单个词 * outValue ->关于这个词的信息:url DIVIDER lineOffset DIVIDER contentOffsetOfLine DIVIDER tfidf DIVIDER isTitle * 如果是标题,则 contentOffsetOfLine 值为 -1 * * @param key 当前行在文件中的偏移位置。 * @param value 当前行的内容。 */ override fun map(key: LongWritable?, value: Text?, context: Context?) { if (key == null || value == null) { return } val lineSegments = value.toString().split(MacroDefines.NEWS_DATA_DIVIDER) if (lineSegments.size < 5) { return // 如果单行分不出五个数据段,就说明这行数据有问题。 } // 把数据换个更好听的名字。 val url = lineSegments[0] val source = lineSegments[1] val date = lineSegments[2] val title = lineSegments[3] val content = lineSegments[4] // content 在文件内的字节位移。 var contentByteOffsetOfLine = 0 // 先设为行在文件中的位移 for (i in 0 until 4) { contentByteOffsetOfLine += lineSegments[i].toByteArray().size + "\u0007".toByteArray().size } // 分词与TFIDF分析。 listOf(title, content).forEachIndexed { index, text ->val jiebaResultList = JiebaSegmenter().process(text, JiebaSegmenter.SegMode.SEARCH) val tfidfResultList = TFIDFAnalyzer().analyze(text, TFIDF_TOP_N) tfidfResultList.forEach { tfidf ->jiebaResultList.forEach { jiebaToken ->if (jiebaToken.word == tfidf.name) { // 成功匹配一个词。 val wordByteOffset = when (index) { 0 ->-1 // 标题 else ->contentByteOffsetOfLine + text.substring(0, jiebaToken!!.startOffset).toByteArray().size } context?.write( Text(jiebaToken!!.word), Text("$url$DIVIDER${tfidf.tfidfvalue}") ) } // if (jiebaToken.word == tfidf.name) } // jiebaResultList.forEach { jiebaToken ->// 如果结巴分词结果没有这个词,则忽略。 } // tfidfResultList.forEach { tfidf ->} // listOf(title, content).forEachIndexed { index, text ->} // override fun map(key: LongWritable?, value: Text?, context: Context?)} 如此即可得到单个网页对单个词的信息。
combine 和 reduce
reduce阶段,每个词的所有网页信息会被收集在一起。我们将它们连起来即可。
我们令输出的 key 与 map 传来的 key 一致,输出的 value 为多个 map 传来的 value 合并的结果。
为减少reduce阶段工作量,我们加入combine过程,执行与reduce阶段同样的工作。
class InvIdxCommonCombiner { companion object { private const val DIVIDER = MacroDefines.SINGLE_INFO_DIVIDER fun combine( key: Text?, values: MutableIterable?, contextWriteCallback: (key: Text, value: Text) ->Unit ) { // 非空检查。 if (key == null || values == null) { return } val resultBuilder = StringBuilder() values.forEachIndexed { index, text ->if (index >0) { resultBuilder.append(DIVIDER) } resultBuilder.append(text) } contextWriteCallback(key, Text(resultBuilder.toString())) } }}class InvIdxCombiner : Reducer() { override fun reduce(key: Text?, values: MutableIterable?, context: Context?) { InvIdxCommonCombiner.combine(key, values) { key, value ->context?.write(key, value) } }}class InvIdxReducer : Reducer() { override fun reduce(key: Text?, values: MutableIterable?, context: Context?) { InvIdxCommonCombiner.combine(key, values) { key, value ->context?.write(key, value) } }} 至此,倒排索引文件创建完毕。
构建二级索引文件
不难发现,二级索引文件特别简单。
class SecIdxMapper : Mapper() { /** * * @param key 词在倒排索引文件中的偏移位置。 * @param value 行信息。 */ override fun map(key: LongWritable?, value: Text?, context: Context?) { if (key != null && value != null) { val word = value.toString().split('\t').first() context?.write(Text(word), Text(key.get().toString())) } }} 你看,它甚至不需要 reduce 阶段。
搜索引擎在线部分
原项目中,我们将客户端与服务端分离,通过socket连接。为简化问题,本文中,我们使用客户端直接读取三个文件,并根据用户输入返回结果。
补充:表示新闻数据的结构。
/* * 整个在线部分最终返回的数据结构: * 字符串。包含多个data。data之间使用 DATA_DIV 分隔。 * 每个 data 按顺序包含如下信息,以 DATA_INTERNAL_DIV 分隔: * tfidf 越大表明越相关 * title * url * author * date * [texts] * texts 由多个小段节选组成。每个节选包含以下内容,以 TEXT_DIV 分隔: * word ->该句之中的关键词 * text ->内容节选 */data class SEText(var word: String = "", var text: String = "") { override fun toString(): String { return "$word${MacroDefines.SERVER_DATA_TEXT_INTERNAL_DIVIDER}$text" }}data class SEResultData( var tfidf: Double = 0.0, var title: String = "", var url: String = "", var author: String = "", var date: String = "", var texts: ArrayList= ArrayList()) { constructor(string: String) : this() { val dataSegments = string.split(MacroDefines.SERVER_DATA_INTERNAL_DIVIDER) tfidf = dataSegments[0].toDouble() title = dataSegments[1] url = dataSegments[2] author = dataSegments[3] date = dataSegments[4] val textStringList = dataSegments[5].split(MacroDefines.SERVER_DATA_TEXT_DIVIDER) textStringList.forEach { textString ->val seg = textString.split(MacroDefines.SERVER_DATA_TEXT_INTERNAL_DIVIDER) if (seg.size >= 2) { texts.add(SEText(seg[0], seg[1])) } else { // TODO 未知错误。 } } } constructor(byteArray: ByteArray) : this(String(byteArray)) override fun toString(): String { val retBuilder = StringBuilder() retBuilder.append(tfidf.toString()) .append(MacroDefines.SERVER_DATA_INTERNAL_DIVIDER) .append(title) .append(MacroDefines.SERVER_DATA_INTERNAL_DIVIDER) .append(url) .append(MacroDefines.SERVER_DATA_INTERNAL_DIVIDER) .append(author) .append(MacroDefines.SERVER_DATA_INTERNAL_DIVIDER) .append(date) .append(MacroDefines.SERVER_DATA_INTERNAL_DIVIDER) val textsBuilder = StringBuilder() texts.forEachIndexed { index, seText ->if (index >0) { retBuilder.append(MacroDefines.SERVER_DATA_TEXT_DIVIDER) } retBuilder.append(seText.toString()) } return retBuilder.toString() } fun toByteArray(): ByteArray { return this.toString().toByteArray() }} 我们要加载二级索引文件。
private fun loadSecondaryIndex(filepath: String): HashMap{ val res = HashMap() val lines = File(filepath).readLines() lines.forEach { line ->val segments = line.split('\t') res[segments[0]] = segments[1].toLong() } return res} 处理部分入口。
private fun getSearchResults( query: String, newsDataFS: RandomAccessFile, invidxFS: RandomAccessFile, secIdxMap: HashMap): List{ val results = ArrayList() ... return results.toList()} 这部分生成一个结果列表。外部将该列表进行一定方式的输出,或转换成字节流通过socket传出,即为搜索结果。
参数解释:
- query: 查询字符串。
- newsDataFS: 原始数据文件流。
- invidxFS: 倒排索引文件流。
- secIdxMap: 二级索引。词到偏移值的映射。
分词。
/* 切分查询内容。 */val jiebaSegments = JiebaSegmenter().process(query, JiebaSegmenter.SegMode.SEARCH)val words = ArrayList()jiebaSegments.forEach { segToken ->words.add(segToken.word)}/* 排序与去重。 */words.sort()for (i in words.size - 2 downTo 0) { if (words[i + 1] == words[i]) { words.removeAt(i + 1) }}/* 去除不在二级索引内的词。 */for (i in words.size - 1 downTo 0) { if (!secIdxMap.contains(words[i])) { words.removeAt(i) }} 处理关于每个词的信息。
/** * url ->se result data */val resultMap = HashMap()println("word list size: ${words.size}")words.forEach { word ->...} 之后,我们可以很开心地针对单个词做研究。
从倒排索引中取词所在行。
invidxFS.seek(secIdxMap[word]!!) val line = invidxFS.readLineUTF8(secIdxMap[word]!!)val urlDataList = line.split('\t')[1].split(MacroDefines.SINGLE_INFO_DIVIDER)println("url data list size: ${urlDataList.size}")urlDataList.forEach { urlData ->...}上方的 readLineUTF8需要自己实现。当然,也可能当你读到此文时,已经有更好的方法读取文章内容了。
现在,我们的处理聚焦到对单个词的单个链接数据。
分析链接数据。
val segments = urlData.split(MacroDefines.SINGLE_INFO_INTERNAL_DIVIDER)val url = segments[0]val lineOffsetOfFile = segments[1].toLong()val wordOffsetOfLine = segments[2].toLong()val tfidf = segments[3].toDouble()val isNewResData: Booleanval seResData = if (!resultMap.contains(url)) { val resData = SEResultData() resultMap[url] = resData isNewResData = true results.add(resData) resData} else { isNewResData = false resultMap[url]!!}seResData.tfidf += tfidfval urlDataLine = newsDataFS.readLineUTF8(lineOffsetOfFile, 200)val urlDataSegments = urlDataLine.split(MacroDefines.NEWS_DATA_DIVIDER)if (isNewResData) { seResData.url = urlDataSegments[0] seResData.author = urlDataSegments[1] seResData.date = urlDataSegments[2] seResData.title = urlDataSegments[3]}if (wordOffsetOfLine != -1L) { // 不是标题。 val contentLine = newsDataFS.readLineUTF8(lineOffsetOfFile + wordOffsetOfLine, 60) val content = contentLine.substring(0, min(20, contentLine.length)) seResData.texts.add(SEText(word, content))}结果效果
至此,我们的搜索引擎制作完毕。它工作得非常好,正如下图所示: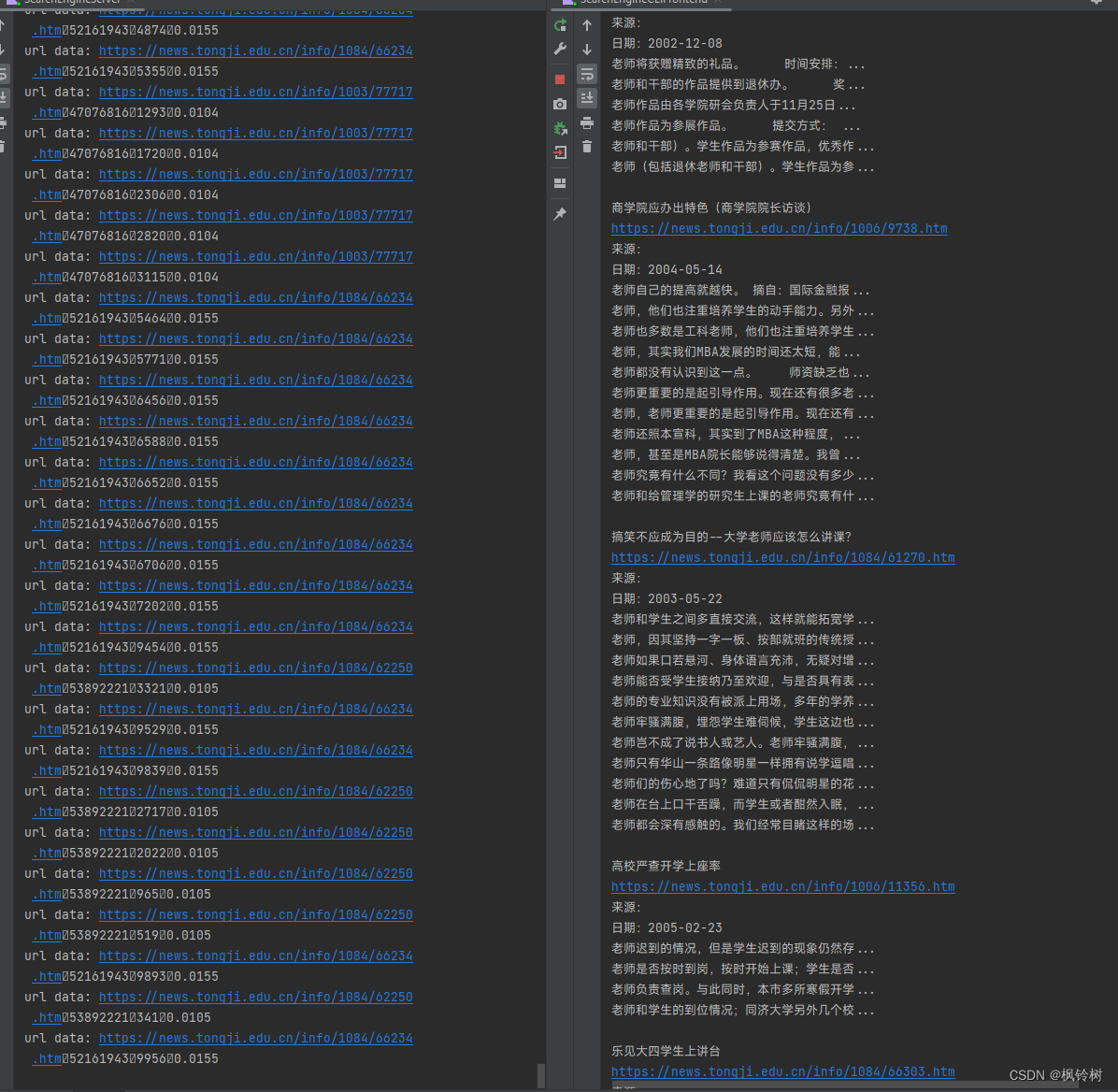
总结
至此,你已经粗略了解一个搜索引擎是如何工作的了,并亲眼见证一个简单的搜索引擎是如何诞生的。
作者水平受限,本文存在不少瑕疵。若有疏漏,烦请指正,感激不尽。
感谢你读到这里。希望本文对你的学习工作有所帮助。








